背景
1、前面文章提到,我们在使用辅助功能的时候遇到了一些数据无法直接抓取,本篇文章主要解决该问题
2、在无法抓取的数据中可以分为两大类
2.1、需要识别内容,比如说
数字、文字
等 
2.2、需要识别图标,比如说
性别标识、转向标识
等 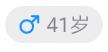
本次主要是为了解决上图的24的识别
开始前的思考1、从常见程度来突破我们平时关注的时候,很多的内容直接告诉你可以识别文字、数字等,并且准确率高达多少多少。这也就反应一个问题,这个场景应用多,并且已经相对成熟,应该是有比较成熟的、简单的方案。
2、从难易程度考虑这个可以参考我们人类识别的过程,我们看到一个东西,把这个东西和我们脑子中的内容做比对,找出相似度最高的,然后输出相似度最高的选项的相关内容。按照人类的万物皆类人的特性,这个识别过程也应该是这样。所以应该是
识别数字的难度>识别图标的难度
思考结果我们从最常见的方案入手,这样的我们可以有更多的参考资料;当然最常见的方案也是最难的方案,在解决这个问题的过程中也会帮我们构建更多的内容,这样在解决较简单但是资料相对较少的资料都时候,我们前面学习的知识也可以使用上了。
开搞在android识别数字这种简单的东西,大家都在用
tess-two
,我们这也从这里讲起。tess-two的集成与简单使用1、添加依赖 implementation 'com.rmtheis:tess-two:9.1.0'
2、下载训练好的数据集
大家可以按需选择,我这边主要是识别数字,所以就选择数字的。 大家可以从这个选择合适的数据集
而我选择了其中的enm.traineddata
3、配置数据集将下载好的数据集放置在
assets
文件夹下4、代码操作1. 将assets下的文件移动到SD下//将识别文件拷贝到SD卡中。目前我这里是不管文件在不在都进行拷贝。
public void OCRfilecopy(Context context) {
//在SD卡中创建存放识别库的目录。该目录名必须是tessdata 这个文件名是在API使用中规定了的。
//定义tessdata目录在SD 卡的路径。
String Chisim_dir = Environment.getExternalStorageDirectory().getAbsolutePath() + "/tessdata";
//定义识别文件的绝对路径和文件名。chi_sim.traineddata 识别文件名。
String orc_filename = Chisim_dir + "/enm.traineddata";
Log.i("path", Chisim_dir);
//检查是否存在此目录。如果存在则不创建,否则则创建目录。
File dirfile = new File(Chisim_dir);
if (dirfile.exists() == false) {
//目录不存在。则创建。
dirfile.mkdir();
Log.i("提示信息", "目录已创建。");
}
//目录创建完成后将OCR识别文件CHI_SIM拷贝到该目录下。
//判断识别文件Chi_sim.traineddata是否存在。
File ocrfile = new File(orc_filename);
//不管识别文件是否存在先删除在创建。
ocrfile.delete();
//开始创建文件。
//首先文件是存放在资源文件夹assets下的。所以要先获取资源;
AssetManager assetManager;
assetManager = context.getAssets();
//开始读取识别文件并开始复制。输入。
InputStream inputStream;
//开始写入文件。输出。
OutputStream outputStream;
try {
//将识别文件读入到输入流中。
inputStream = assetManager.open("enm.traineddata");
//创建目标文件。
outputStream = new FileOutputStream(orc_filename);
//开始复制,每次复制1024k的字节。
byte buff = new byte;
//开始循环写入。
int ll_count;
while ((ll_count = inputStream.read(buff)) != -1) {
outputStream.write(buff, 0, ll_count);
}
//释放资源
outputStream.flush();
outputStream.close();
inputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
2. 初始化tess-two sdk
//定义使用的字符集。
String orctype = "enm";
//实例化 ocr API
TessBaseAPI tessBaseAPI = new TessBaseAPI();
//开始初始化 指定识别所用的资源位置。在SD卡中的位置。
tessBaseAPI.init(Environment.getExternalStorageDirectory().getAbsolutePath() , orctype);
tessBaseAPI.setVariable(TessBaseAPI.VAR_CHAR_WHITELIST, "0123456789");
tessBaseAPI.setVariable(TessBaseAPI.VAR_CHAR_BLACKLIST, "ABCDEFGHIJKLMNOPQRSTUVWYZabcdefghijklmnopqrstuvwxyz!@#$%^&*()_+=-}{;:'"|~`,./<>?…】丨");
tessBaseAPI.setPageSegMode(TessBaseAPI.PageSegMode.PSM_SINGLE_LINE); //设置识别模式
3. 进行识别
String number = "";
//初始化后开始识别图片。设置需要识别的图片。
tessBaseAPI.setImage(bitmap);
//得到识别内容
number = tessBaseAPI.getUTF8Text();
Log.i("提示信息", "number=" + number);
5、tess-two的注意事项
1、需要尽量的保证保证数据集的范围精确,这样才能更好地识别。
所以初始化sdk的时候,设置黑白名单以及识别模式都非常的有必要
2、在完成上述操作之后发现确实可以识别数字了,但是识别率比较低。查找资料之后感觉和背景的复杂度有关系。于是就要想办法将内容和背景进行区分。
后续规划1、下一部分会讲opencv的简单使用
2、下一部分会将图片相似度的简单使用
关注: arigeweixin ,取得更多联系 